Image-to-Markup Generation with Coarse-to-Fine Attention
Yuntian Deng, Anssi Kanervisto, Jeffrey Ling, Alexander M. Rush
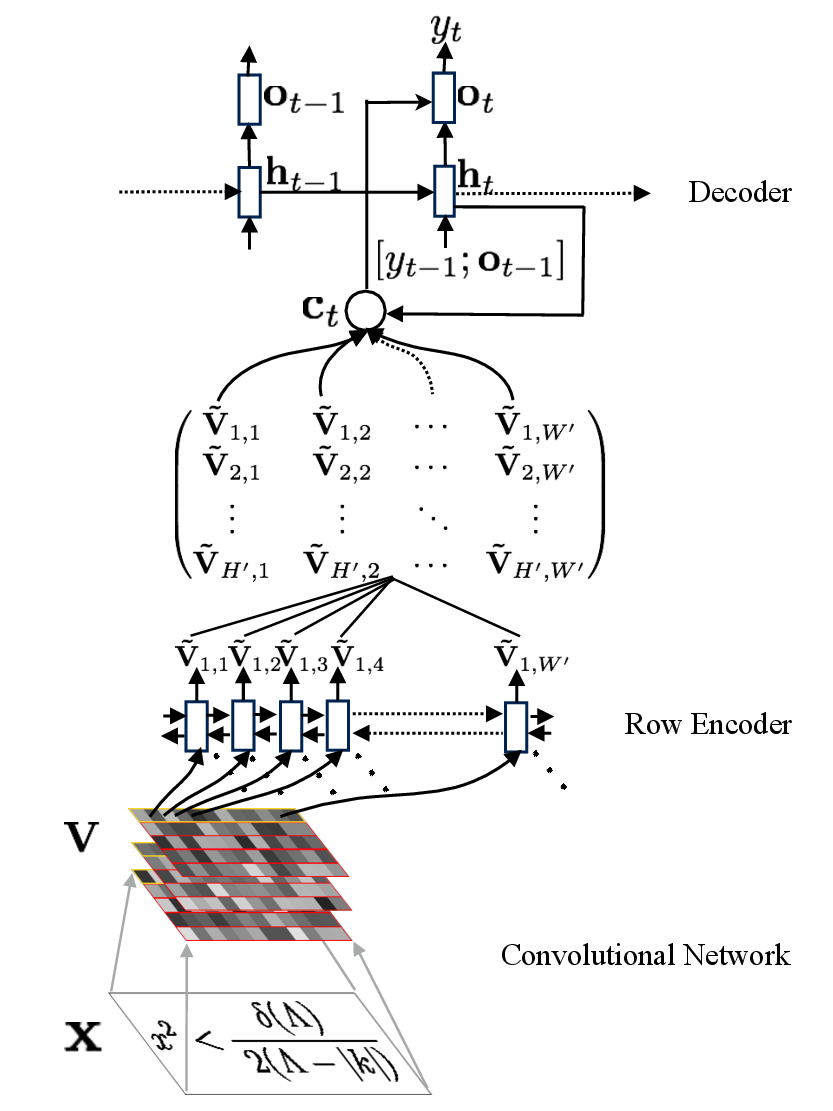
We present a neural encoder-decoder model to convert images into presentational markup based on a scalable coarse-to-fine attention mechanism. Our method is evaluated in the context of image-to-LaTeX generation, and we introduce a new dataset of real-world rendered mathematical expressions paired with LaTeX markup. We show that unlike neural OCR techniques using CTC-based models, attention-based approaches can tackle this non-standard OCR task. Our approach outperforms classical mathematical OCR systems by a large margin on in-domain rendered data, and, with pretraining, also performs well on out-of-domain handwritten data. To reduce the inference complexity associated with the attention-based approaches, we introduce a new coarse-to-fine attention layer that selects a support region before applying attention.
Please let us know what you think by commenting below or contacting @yuntiandeng on twitter.